はじめてのAI開発!必要なデータ作りと学習環境、推論モデルの基礎まとめ
........
- 更新日
- 公開日
- 2026.03.09

AI開発を始めたいと考えている方にとって、開発環境の選択は最初の大きな課題です。特に画像認識を中心としたAI(機械学習)では、LinuxとGPUを使った開発環境づくりが主流となっています。
本記事では、AI開発の全体の流れ、「情報収集 → アノテーション → 学習 → 推論 → 再学習」の流れを、初心者の方にも分かるように解説します。
-

【記事】Linux基礎まる分かり!導入から長期運用まで見据えたポイント整理

-
Linuxの基本概念から最新動向について知りたい方は、こちらの記事をご覧ください。
INDEX
1. 最初に理解すべき、AI開発の全体像
AI開発の流れは、どのテーマでもほぼ次の3ステップになります。
①学習データを集める・作る(情報収集・アノテーション)
②集めたデータでAIを育てる(学習・再学習)
③学習したAIを実際の機械で動かす(評価ボードで推論)
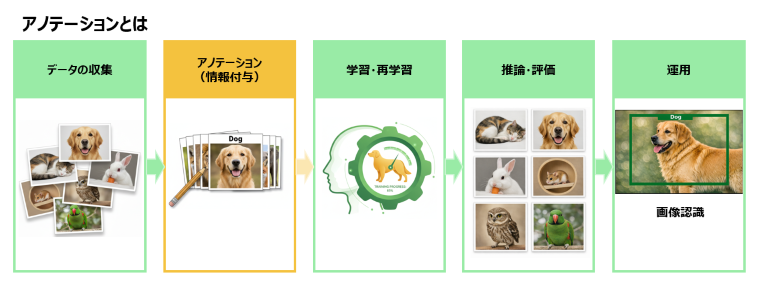
AIの賢さは、用意するデータの質に大きく左右されます。そして「学習」に最も時間がかかるため、GPUが重要になります。また、学習を高速に行うためのNVIDIAの技術(CUDA)はLinux上で最大の性能を発揮するため、AI開発はLinuxがベースになっています。
AIを活用する際の重要なポイントは、AIが導き出す結果は推論であり、必ずしも正解ではないということです。AIは学習モデルを通じて論理的に推理した結果であるため、「推論」と呼ばれます。この特性を理解したうえで、適切なデータセットと学習方法を選択することが、高精度なAIシステムの構築につながります。
|
CUDA NVIDIAが提供するCUDA(Compute Unified Device Architecture)という並列計算用プラットフォームで使われる命令や関数の総称です。C/C++を拡張した言語やAPIを使い、GPUの並列処理能力をAIの学習や推論に活用できます。 |
-

【記事】ChatGPTと作ってみた組み込みAI~WebアプリでAIじゃんけん~
-
AIモデル作成について詳しく知りたい方は、こちらの記事をご覧ください。
-
GPUについて詳しく知りたい方は、こちらの記事をご覧ください。
-

【記事】AI分野で欠かせないGPUとは?CPUとの違いや活用例まで解説
2. AI開発における重要な用語の理解
AI開発において、基本用語の理解はとても重要です。ここでは、データセットの概念や学習モデルの役割などについて解説します。
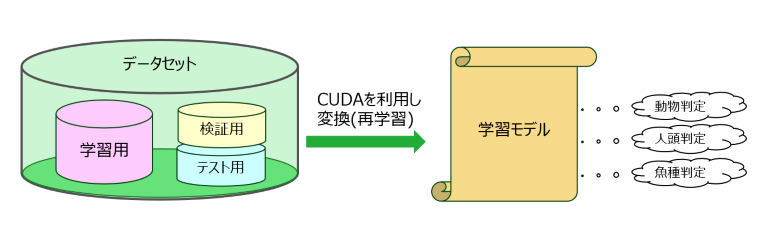
データセットの概念と必要な規模
データセットは、AIが判断をするために必要なデータの集まりです。例えば、画像であればJPGやPNG、音声であればWAVやMP3、テキストであればテキストファイルやDOCなど、AIに判断させたいデータ形式に合わせた大量のデータが必要です。一般的には、各カテゴリごとに最低限100個程度のデータセットが必要とされていますが、100個では判定精度は低くなります。AIを実用レベルに引き上げるには、1カテゴリごとに最低1000個程度、商用レベルでは最低1万個程度が必要とされています。
データセットは、学習用データ、検証用データ、テスト用データの3つに分けられます。学習用データでAIを学習し、検証用データで学習したAIの判定処理を検証し、最終的な確認用としてテスト用データを使用します。配分比率はさまざまな案がありますが、7対1.5対1.5が平均とされています。つまり学習用データで全体の3分の2以上を占め、残りを検証用とテスト用で配分するケースが多くなっています。
学習モデルとその役割
学習モデルは、データセットで学習した結果をもとに、入力された情報を出力情報に結びつける判断を行うため、とても重要です。この学習モデルを切り替えることによって、同じ画像でも判断結果は変わります。
学習モデルは実質的に、入力されたデータに対して幾重にも重なった計算を行い、特徴的なところを抽出して判断します。この演算式は浮動小数点演算という計算を大量に組み合わせており、これがGPU環境を必要とする理由となっています。AI学習は膨大な計算を行うため、CUDA対応GPUがないと実用的な学習は困難です。
AIは最初、何もない状態では画像に対してそれが何かを理解できず、当然ながら推測や推論をすることはできません。データセットから作り出した学習モデルをもとにして、画像の中から特徴的なところを探し出し、その特徴が学習モデルの中のどれに似ているかを推論し、結果を導き出します。
3. 現代AIの主な4つのカテゴリ
現代のAI技術は、主に4つのカテゴリに分類されます。これらを理解することで、自身のプロジェクトに最適なAI技術を選択できます。

自然言語処理
自然言語処理とは、作成されたテキストを集約し、ユーザの指示に応じてテキストを生成したり、質問に対して回答を生成したりする技術です。OpenAIのChatGPTに代表されるこの技術は、プロンプトの解釈、要素の分析、回答の生成、フィードバック学習という4つの段階で構成されています。GoogleのGemini、MicrosoftのCopilotなどもこの分野で競合しています。
データ認識
データ認識とは、音や振動などのデータを認識し、テキスト化したり、異常な稼働音を検知したりする技術です。例えば、工作機械が正常に動作している際の音声を蓄積し、数か月後にロータリーベルトの緩みによる異常を検知するといった活用が可能です。人の耳では分からない微細な変化もAIで判断し、故障を予知することができます。
画像認識
画像認識とは、入力された画像に対して、どの種類の画像に最も近いかを判断する技術です。データセットと学習モデルという2つの要素を理解する必要があり、画像内の特徴点を抽出して判定を行います。これは、動物検知など、写真内の特定領域を判断するケースが主流となっています。
予測異常検知
予測異常検知とは、相談情報や販売データ、製造管理データなど、過去に蓄積されたさまざまなデータを多角的に分析し、将来の状況を予測したり異常な状態を検知したりする技術のことです。例えば、コンビニのPOSデータと天気データを組み合わせて商品需要を予測するような活用が挙げられます。
4. AI開発で使用される主要なツール
AI開発は「データを作る → AIを育てる → 実機で動かす」という流れで進みます。ここでは、その要(かなめ)となるアノテーションツールと再学習ツールを中心に、初心者にもわかる言葉で解説します。
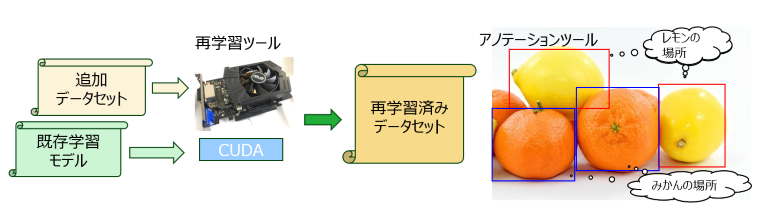
4-1. アノテーションツール(AIに“正解”を教える)
AIは、データをただ眺めているだけでは学べません。画像や音のどの部分が何なのかを、人間が「正解ラベル」として教える必要があります。これがアノテーションです。
■何をするツール?
画像なら対象物を四角で囲い、「cat」「lemon」のようなタグを付けます。音なら、異音の区間にタグを付けます。
■なぜ重要?
学習の出発点は「正解の基準」です。ラベル付けが曖昧だったり、画像ごとに基準が揺れていたりすると、AIは誤ったルールを覚えてしまい、精度が不安定になります。
■実務のコツ
1) タグの命名ルールを先に決める
2) 代表例を作ってメンバーで共有する
3) 迷う画像は後で見直せるようフラグを立てる
といった“運用ルール”を整えるだけで、品質が上がります。
4-2. 再学習ツール(AIを“育てる”)
正解ラベルの付いたデータを使い、AIの判断力を鍛える工程が 学習/再学習 です。再学習ツールは、すでにあるモデルに新しいデータを与えて精度を引き上げたり、苦手な条件(夜間・逆光・新しい品種など)を克服させたりするための“育成エンジン”です。
■何ができる?
データ読み込み、画像サイズや学習回数(Epoch)の設定、学習の実行、学習後の精度確認(混同行列・再現率など)の表示、モデルの書き出し、までをひとつの画面で行えます。
■なぜ GPU(CUDA)が必要?
学習は巨大な行列計算の連続です。CPU だけだと数十時間~数日かかる処理が、CUDA 対応の NVIDIA GPU を用いることで現実的な時間に短縮され、改善の試行回数を増やせます。
■設定の考え方
・学習回数(Epoch)
上げると精度は伸びやすいが、やりすぎると 過学習(覚え込み)になります。
・学習率(Learning Rate)
大きすぎると不安定、小さすぎると収束が遅くなります。まずはデフォルト→学習曲線を見て微調整してください。
・データ拡張
明るさ・回転・切り出しなどで“現場の揺らぎ”を仮想的に再現してください。少量データでも実用精度に近づけやすくなります。
|
過学習 学習データに最適化されすぎ、学習データに近い入力では高精度でも、特徴が外れた未知データでは精度が大きく低下してしまう現象です。 |
5. 再学習データの活用方法(一般的な推論の仕組みとモデル変換の考え方)
AIモデルは、学習が完了しただけでは実際の機器上でそのまま動かせるわけではありません。多くの場合、学習環境(PC/GPU)で使われるモデル形式と、実際に動かす機器(エッジデバイス・評価ボード・組み込み機器)の対応形式が異なるため、推論用に変換する工程が必要です。
● 推論(Inference)とは?
推論とは、学習済みモデルを使って「これは猫か?」「異常音か?」「物体はどこにある?」と判断させる処理のことです。学習時の処理(大量のデータを何度も計算する)のような重い計算ではなく、1枚の画像・1つの音声を素早く判定する“軽い計算”が中心になります。
そのため推論では、以下が重視されます。
・ 軽量で高速に動くモデル形式
・ デバイスに合った最適化
・ 限られたメモリでも動作する構造
この理由から、学習したそのままのモデルを使うのではなく、推論向けに変換(コンパイル)して最適化する必要が出てくるのです。
● 推論用モデルへの変換が必要な理由
AIモデルの開発環境と実行環境は、多くの場合異なります。
たとえば:
・ 学習時 → PyTorch・TensorFlow などで動作
・ 実行時 → エッジ機器や組み込みデバイスへ搭載
→ CPU / GPU / NPU / DSP / DRP-AI など、使える回路が全く違う
この差を埋めるため、各ハードウェアに適した形へ「変換(コンパイル)」する工程が必要になります。
一般的な流れとしては次のようになります:
1. 学習済みモデルをエクスポート 例:ONNX、HDF5、SavedModel、.pth など
2. 推論用ランタイムに合わせて変換 例:TensorRT、OpenVINO、TVM、CoreML など
3. デバイス向けに最適化(量子化・軽量化)
4. 実機に転送
5. 推論エンジンで実行
推論モデルは軽量かつ高速である必要があるため、変換と最適化は AI を「現場で使える」状態に仕上げる最終工程といえます。
6. まとめ
AI開発は、データを収集・作る→学習して育てる→実機で動かすという流れで進みます。特に、最初のデータ作りは AIの精度を左右する重要な工程です。アノテーションの基準が揃っていなかったり、データにブレがあると、その誤差は後の学習では補いにくく、精度の限界につながります。
学習・再学習の工程では、CUDA対応GPUを備えたLinux環境を使うことで、効率よく改善サイクルを回せます。また、完成したモデルはそのままでは実機で動かないため、推論向けに最適化・変換する作業も欠かせません。
AI開発をうまく進めるポイントは、質の高いデータを収集・作り、適切に学習させ、実機に合わせて最適化すること。この流れを押さえることで、長期的に高精度なAIを運用できる基盤を確立することができます。
(執筆者:高橋利典 編集者:大沼正人)